
This is Ryusei__46 speaking.
The content of this article is exactly what the title suggests. While there are plenty of articles available online explaining "how to subtitle videos using Python," I found that when trying to implement more advanced features, there were often gaps in the available information. That's why I've decided to share my complete experience with you.
Previously, I developed a desktop application called "Transmedia." This tool automatically transcribes foreign-language videos and audio content (primarily English), then translates the transcript into Japanese using DeepL, and finally displays the content with synchronized subtitles through a dedicated player.
メディアの文字お越しと翻訳、専用のプレイヤーを搭載したアプリケーションです。. Contribute to ryusei-48/transmedia development by creating an account on GitHub.
When developing this app, we needed to implement robust Python text processing capabilities. We're using the "Whisper" machine learning model, which is an open-source library provided by OpenAI—the same library we'll be discussing in this article.
Now that we've covered the app's development, let's move on to the main content of this article.
Checking execution environment
My execution environment (hardware) is as follows:
- Operating System: Windows 11 Pro 64-bit
- CPU: AMD Ryzen 9 5900X 12-core Processor
- GPU: NVIDIA GeForce RTX 2060 SUPER 8GB
- Memory: DDR4 32GB 3200MHz
- Storage: M.2 NVMe SSD 1TB with Read/Write speeds of 7000MB/s
Run OpenAI's "Whisper" model on the above hardware configuration.
For using the "Whisper" model, we'll be using the "faster-whisper" Python library in this implementation.
Faster Whisper transcription with CTranslate2. Contribute to SYSTRAN/faster-whisper development by creating an account on GitHub.
The "faster-whisper" library we'll be using here is an open-source project that delivers superior performance compared to OpenAI's official library. Specifically, it achieves:
- Significantly faster processing speeds (approximately five times quicker than the official library)
- Approximately 30%-40% reduction in memory usage
Unless there's a specific reason not to, we recommend using this library—especially for those with limited VRAM resources.
Preparing to use Whisper model
As a prerequisite, you'll be using Python, so if you're not yet set up to run Python on Windows, we recommend referring to the following site. Separate guides are available for Mac and Linux users as well.

ここでは、Pythonの未経験者の学習用に、Pythonをインストールする方法を、Windows、macOSなど、環境別に解説しています。 当サイトでは、Pythonの質問は受け付けていません。インストールで困ったら、 Python.jp Discordサーバ な
First, let's install "pytorch," the dependency library required for faster-Whisper, which is used for machine learning operations.
PyTorchとは
PyTorch is an open-source machine learning library for Python that provides tools for performing deep learning. Initially developed by Facebook's artificial intelligence research group in 2016, it has since become one of the most popular machine learning libraries in Python.
This "pytorch" installation process is somewhat tricky. If you're using a PC without a graphics card, you'll need CPU processing—in this case, pytorch installation is straightforward. You can install it using the following pip command:
pip3 install torch torchvision torchaudioHowever, if you want to perform processing using a graphics card, you'll also need to set up the environment for using "CUDA." You'll also need to install "CUDNN" simultaneously. "CUDNN" is a deep learning architecture that runs on top of "CUDA."
What is CUDA?
CUDA (Compute Unified Device Architecture) is a platform developed by NVIDIA for parallel computing using graphics processing units (GPUs). CUDA enables high-speed processing of large datasets by fully leveraging the capabilities of GPUs.
While the Whisper model can technically run on CPUs alone, attempting to use the highest-accuracy models like "large-v2" or the recently released "large-v3" by OpenAI is extremely time-consuming. Depending on CPU performance, on my PC, processing audio took more than twice the original duration.
When tested on a graphics card, the "RTX 2060 SUPER" completed processing in about one-fifth of the original time. Clearly, graphics cards offer dramatic speed improvements, so if you have a PC with a GPU, I strongly recommend setting up CUDA support.
Verify CUDA and CUDNN compatible versions
First, go to the PyTorch official "GET STARTED" page and check the supported CUDA version.

Set up PyTorch easily with local installation or supported cloud platforms.
The article mentions that CUDA 12.1 is supported. This time, we'll be using version 12.1.
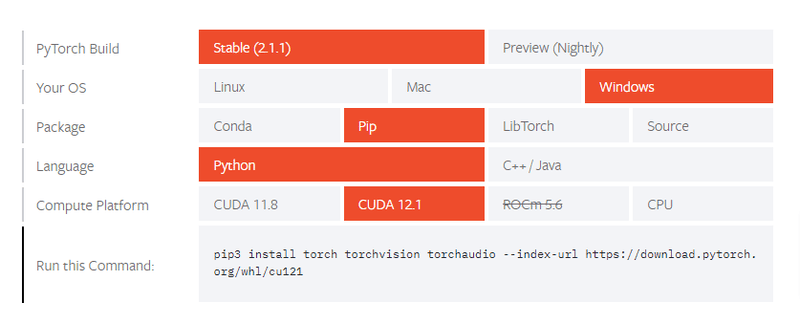
This page also allows you to install PyTorch by selecting the appropriate configuration options. Once CUDA and CUDNN are installed, execute this pip command to complete the installation.
Next, open the CUDA "Support Matrix - NVIDIA Docs" page to verify compatibility between your CUDA version, operating system, NVIDIA driver version, and the GPU architecture you are using.
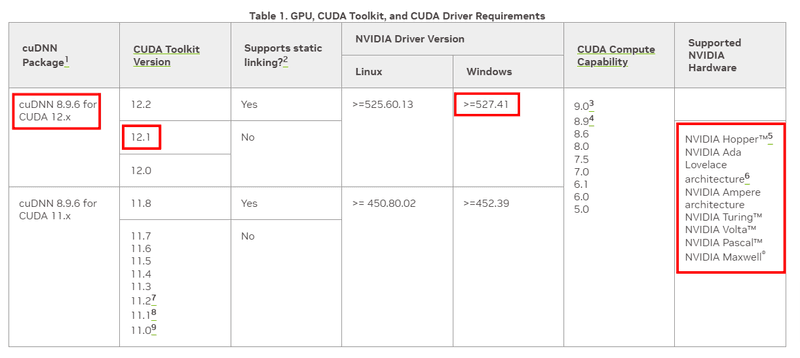
For "NVIDIA Driver Version," if you have installed the graphics card driver, the "NVIDIA Control Panel" tool should be installed. You can search for and launch the app by pressing "Win + Q" on your keyboard.
The "Supported NVIDIA Hardware" section can be somewhat confusing—it refers to the names of the architectures implemented in individual graphics cards. You can verify the architecture of your specific graphics card by checking the "List of Nvidia graphics processing units."
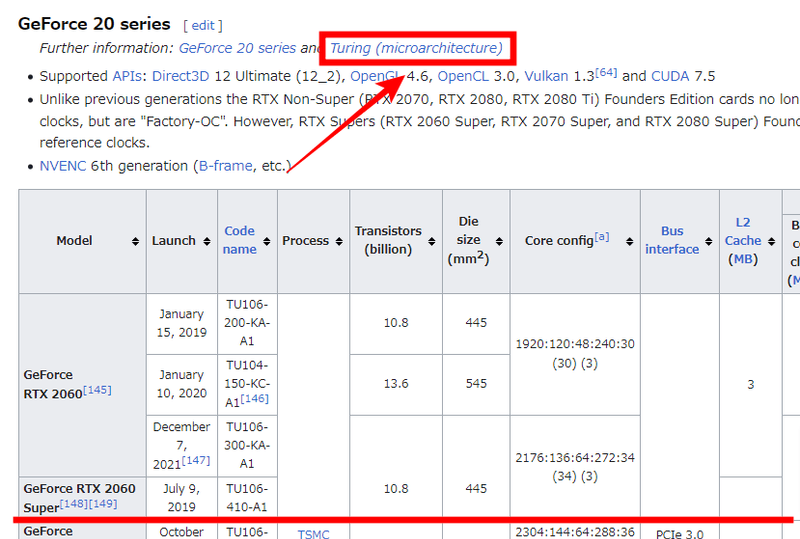
This page contains comprehensive details about all generations of graphics cards, making it quite extensive. You can use the keyboard shortcut "Ctrl + F" to search through the page and locate your specific graphics card. In my case, I have a "GeForce RTX 2060 SUPER," which falls under the "GeForce 20 series" and uses the "Turing" architecture.
Therefore, for "Supported NVIDIA Hardware" you should see "NVIDIA Turing" confirming that there are no compatibility issues.
Install Build Tools for Visual Studio
Before installing CUDA, you must first install "Build Tools for Visual Studio." Without this, the CUDA Toolkit won't function properly.

Download Visual Studio IDE for free. Try out Visual Studio Professional or Enterprise editions.
Scroll to the bottom of this page where you'll find the "All Downloads" section. Select "Tools for Visual Studio," then open the accordion to expand it. Inside, you'll see "Build Tools for Visual Studio 2022," so click "Download" to obtain the installer.
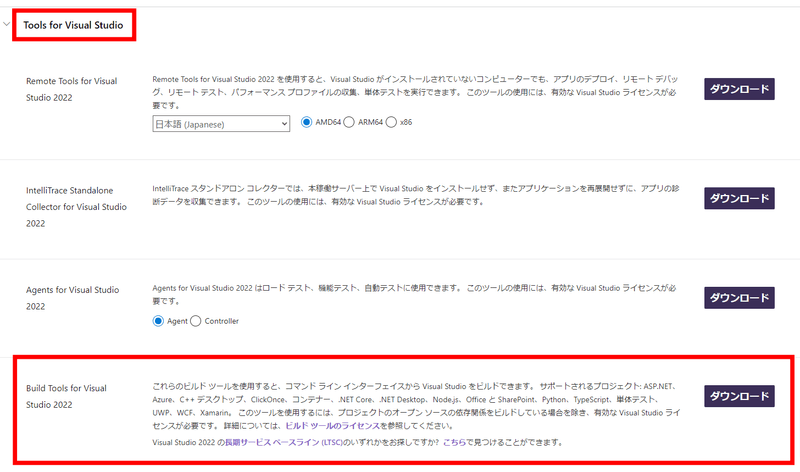
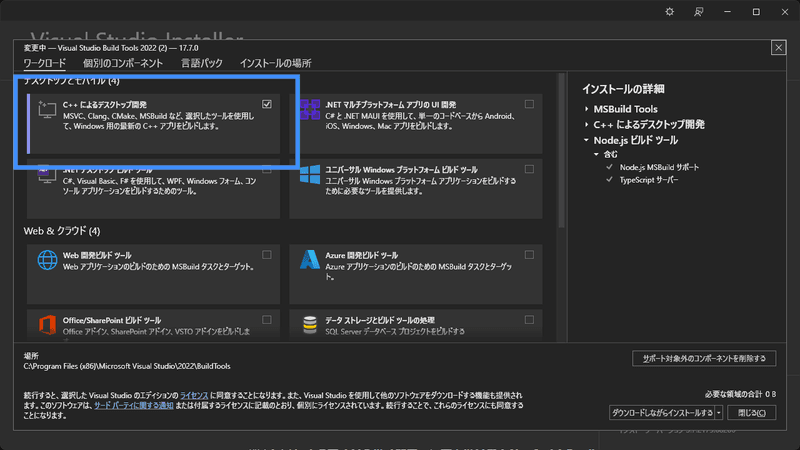
When launching the installer, you'll see a screen like this—please check the box for "Desktop Development with C++" to complete your installation.
Installing CUDA and CUDNN
Now, let's proceed with installing the confirmed versions of "CUDA Toolkit" and "CUDNN" on Windows.
To install CUDA Toolkit, open the "CUDA Toolkit Archive" page. Since I'm using version 12.1, click "CUDA Toolkit 12.1.0 (February 2023)".
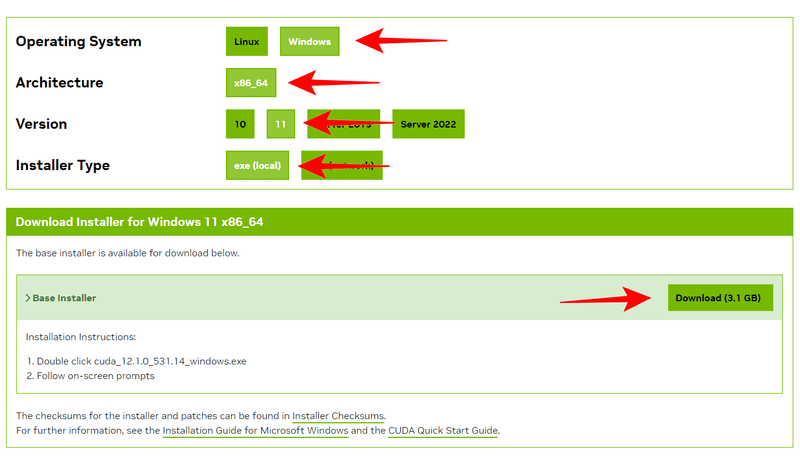
The download screen allows you to select the appropriate installer type for your environment.
Once the installer is downloaded, simply run it to complete the installation.
To verify that CUDA has been installed successfully, execute the following command in Command Prompt or PowerShell:
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_May__3_19:00:59_Pacific_Daylight_Time_2022
Cuda compilation tools, release 12.1, V11.7.64
Build cuda_12.1.r11.7/compiler.31294372_0Next, install "CUDNN" by opening the NVIDIA cuDNN page and clicking the "Download cuDNN Library" button. If this is your first CUDNN download, account registration is required—please complete this step independently.

On the next screen, checking "I Agree To the Terms of the cuDNN Software License Agreement" will display the available CUDNN versions for download. For my case, I selected "Download cuDNN v8.9.6 (November 1st, 2023), for CUDA 12.x," then clicked "Local Installer for Windows (Zip)" from the installer download links displayed below to download the ZIP-compressed file containing the installer.
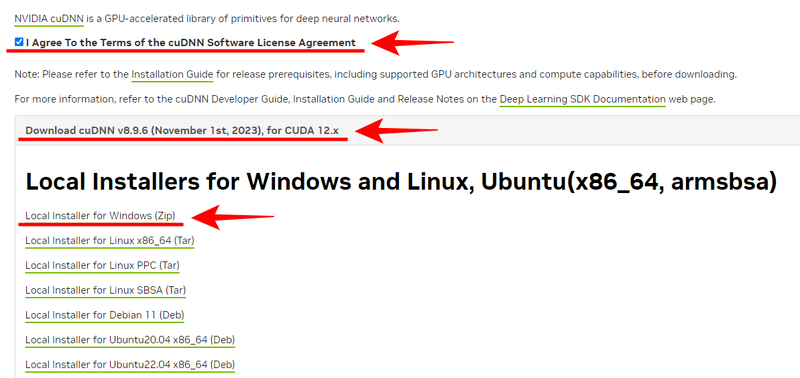
The downloaded ZIP file contains three folders: "bin", "include", and "lib". You should overwrite these files in your CUDA installation directory. The CUDA installation path is typically C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1. After overwriting these files, the CUDNN installation is complete.
Installing "PyTorch" and "Faster-Whisper"
Now that PyTorch is ready for CUDA usage, open PyTorch's official "GET STARTED" page and copy the installation command that matches your environment.
For me, these are the settings: "PyTorch Build: Stable (2.1.1)", "Your OS: Windows", "Package: Pip", "Language: Python", and "Compute Platform: CUDA 12.1".
Finally, copy the installation command displayed under the "Run this Command:" section.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121This should now enable CUDA functionality in PyTorch. To verify CUDA is activated, execute the following code in either Python's interactive mode or through a Python script file:
import torch
torch.cuda.is_available() // trueが出力されればOKNext is installing "Faster-Whisper", which can be completed by running the following command:
pip3 -U install faster-whisperNow you're ready to transcribe using the Whisper model.
Practicing Transcription with "Faster-Whisper"
If you want to simply convert transcript text into bullet points, you can use the following code:
from faster_whisper import WhisperModel
model_size = "large-v2"
model = WhisperModel(model_size, device="cuda", compute_type="int8")
# or run on GPU with INT8
# model = WhisperModel(model_size, device="cuda", compute_type="int8_float16")
# or run on CPU with INT8
# model = WhisperModel(model_size, device="cpu", compute_type="int8")
fileName = "audio.m4a"
segments, info = model.transcribe(
"audio.m4a", word_timestamps=True,
initial_prompt="こんにちは、私は山田です。最後まで句読点を付けてください。",
beam_size=5, language='ja'
)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
with open("transcribed.txt", 'w') as f:
for segment in segments:
f.write( segment.text + "\n" )
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))model_size should be
- tiny: 39MB / Fast processing but lower accuracy
- base: 74MB
- small: 244MB / Default model
- medium: 769MB
- large: 1550MB / Slower processing but highest accuracy
- large-v1: 1550MB / Updated version of the large model
- large-v2: 1.54GB / Latest version with highest accuracy (until "large-v3" was released in late September 2023)
- large-v3: Current latest model
You can specify sizes as described above. Higher sizes provide better accuracy but increase processing load and memory usage. For using faster-whisper, even the highest-accuracy large-v2 model should work with approximately 6GB of VRAM.
compute_type can be set to int8, float16, or float32. This parameter configures how the Whisper model processes numerical values—higher precision levels improve accuracy but increase computational load.
word_timestamps determines whether to include the start and end times of each word's appearance in the output. You can access word-level information using segment.words. This is particularly useful for fine-tuning your data processing.
initial_prompt is a parameter for specifying the initial instruction given to the Whisper model. In this example, we've set it to "Hello, I'm Yamada. Please maintain proper punctuation throughout." This provides guidance to ensure the model properly inserts punctuation and segments the output at appropriate points.
language specifies the language of the audio or video file being processed. While automatic detection is available, specifying the language manually reduces processing overhead and improves performance.
Format and output results to a JSON file
Using the code I've created below, you can output all data including word-level information.
// transcribe.py
import sys, glob, json, re
print("########## Start of character arrival ##########")
try:
from torch import cuda
from faster_whisper import WhisperModel
except ImportError:
sys.stderr.write("「faster_whisper」か「pytorch」モジュールが見つかりません。\n")
sys.exit(1)
mediaSourcePath = sys.argv[1]
mediaFilePath = glob.glob( f"{ mediaSourcePath }\\*" )[0]
model_size = sys.argv[2]
useLang = sys.argv[3] if sys.argv[3] else None
transcribe_results = []
plasticated_result = []
model = WhisperModel(
model_size, compute_type="float16",
device= 'cuda' if cuda.is_available() else 'cpu'
)
segments, info = model.transcribe(
mediaFilePath, beam_size=5, word_timestamps=True,
initial_prompt="こんにちは、私は山田です。Hello, I am Yamada.",
language=useLang
)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
transcribe_tmp = { "start": segment.start, "end": segment.end, "subtitle": segment.text, "word_timestamps": [] }
for word in segment.words:
transcribe_tmp["word_timestamps"].append({ "start": word[0], "end": word[1], "text": word[2] })
transcribe_results.append( transcribe_tmp )
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
with open( f"{ mediaSourcePath }\\transcribe.json", "w", encoding="utf-8" ) as json_file:
json.dump( transcribe_results, json_file, indent=2, ensure_ascii=False )
if len( glob.glob( f"{ mediaSourcePath }\\transcribe.json" ) ) > 0:
word_tmp, word_start_tmp, skip_flag = "", 0, False
for transcribe in transcribe_results:
for word in transcribe["word_timestamps"]:
word_tmp += word["text"]
if not skip_flag:
word_start_tmp = word["start"]
skip_flag = True
if re.search( r"(\.|\?|。)$", word["text"] ):
plasticated_result.append({
"start": word_start_tmp,
"end": word["end"], "text": re.sub( r"^\s+", "", word_tmp )
})
skip_flag = False
word_tmp = ""
with open( f"{ mediaSourcePath }\\plasticated.json", "w", encoding="utf-8" ) as json_file:
json.dump( plasticated_result, json_file, indent=2, ensure_ascii=False )
with open( f"{ mediaSourcePath }\\plasticated.plain.txt", mode="w", encoding="utf-8" ) as txt_file:
for index, plasticated in enumerate( plasticated_result ):
txt_file.write( str( index ) + ': ' + plasticated['text'] + "\n" )Pass arguments when running from the command line.
$ py transcribe.py [media_source_path] [model_size] [language]For media_source_path, place your prepared video or audio files in any desired folder and specify the full path to that folder. For model_size, enter the name for your desired model size (e.g., base or small). For language, specify the language code of the media to be processed; if left unspecified, it will default to automatic detection.
// transcribe.json
{
{
"start": 8.540000000000003, // 出現開始時刻(秒)
"end": 10.88, // 出現終了時刻
"subtitle": " Introducing Apple Vision Pro.", // 文字お越しされたテキスト
"word_timestamps": [ // 更に細分化された単語ごとの情報
{
"start": 8.540000000000003,
"end": 9.280000000000001,
"text": " Introducing"
},
{
"start": 9.280000000000001,
"end": 10.02,
"text": " Apple"
},
{
"start": 10.02,
"end": 10.42,
"text": " Vision"
},
{
"start": 10.42,
"end": 10.88,
"text": " Pro."
}
]
},
{
"start": 12.16,
"end": 16.0,
"subtitle": " The era of spatial computing is here.",
"word_timestamps": [
{
"start": 11.870000000000001,
"end": 12.24,
"text": " The"
},
{
"start": 12.24,
"end": 12.62,
"text": " era"
},
{
"start": 12.62,
"end": 12.96,
"text": " of"
},
{
"start": 12.96,
"end": 13.28,
"text": " spatial"
},
{
"start": 13.28,
"end": 13.8,
"text": " computing"
},
{
"start": 13.8,
"end": 15.58,
"text": " is"
},
{
"start": 15.58,
"end": 16.0,
"text": " here."
}
]
},
// ・・・・・・・以下省略
}The "plasticated.json" file processes the data from "transcribe.json" by organizing word-level data, grouping Japanese sentences up to "。" and English sentences up to ". (period)" as single segments.
// plasticated.json
{
{
"start": 8.540000000000003,
"end": 10.88,
"text": "Introducing Apple Vision Pro."
},
{
"start": 11.870000000000001,
"end": 16.0,
"text": "The era of spatial computing is here."
},
{
"start": 22.57,
"end": 27.38,
"text": "When you put on Apple Vision Pro, you see your world and everything in it."
},
// ・・・・・・・以下省略
}Using this data, I believe we can flexibly adapt to various applications.
Create SRT Files (Subtitles)
An SRT file (SubRip Subtitle File) is a format used for displaying subtitles alongside video content. It is supported by most media players and is commonly used to add subtitles to videos.
When adding subtitles to video editing projects, you would typically have to manually transcribe text and insert it as text. However, by using Python and Whisper, you can automate both the transcription process and SRT file creation, significantly reducing workload and improving workflow efficiency.
If you only need to use an SRT file with subtitles while playing a video in a media player, you can simply name the SRT file to match the video file and place them in the same directory—the player will automatically load it. For more detailed information, see Microsoft's guide "How to use SRT files to display subtitles during video playback".
The following code can be used to create SRT files:
// srt-whisper.py
from faster_whisper import WhisperModel
import math, sys
def convert_seconds_to_hms(seconds):
hours, remainder = divmod(seconds, 3600)
minutes, seconds = divmod(remainder, 60)
milliseconds = math.floor((seconds % 1) * 1000)
output = f"{int(hours):02}:{int(minutes):02}:{int(seconds):02},{milliseconds:03}"
return output
media_path = sys.argv[1]
language = sys.argv[2]
model_path = sys.argv[3]
model = WhisperModel(model_path, device="cuda", compute_type="int8")
segments, info = model.transcribe(
media_path,
initial_prompt="こんにちは、私は山田です。最後まで句読点を付けてください。",
beam_size=5, language="ja"
)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
count = 0
with open(media_path, 'w') as f: # Open file for writing
for segment in segments:
count +=1
duration = f"{convert_seconds_to_hms(segment.start)} --> {convert_seconds_to_hms(segment.end)}\n"
text = f"{segment.text.lstrip()}\n\n"
f.write(f"{count}\n{duration}{text}") # Write formatted string to the file
print(f"{duration}{text}",end='')Pass the following arguments on the command line:
$ py srt-whisper.py [media_path] [language] [model_size]Executing this will generate a SRT file in the current directory with the same name as the media file.
That concludes the article content.
Recently, we've released "Transcriber," a fully private web app for speaker separation transcription—we'd be delighted if you gave it a try.

Transcribe audio files accurately, entirely in your browser. Your audio never leaves your device, so it stays completely private. Speaker diarization powered by Whisper AI is also supported.
Referenced Websites

Hi, really great implementation, congratulations. The only thing I missed was saving to a format such as srt or vtt, I decided to add such a function for myself. I'm not a programmer, that's why I ...